
Churn Prediction
3. Machine Learning for Classification
We’ll use logistic regression to predict churn
3.1 Churn prediction project
- Dataset: https://www.kaggle.com/blastchar/telco-customer-churn
- https://raw.githubusercontent.com/alexeygrigorev/mlbookcamp-code/master/chapter-03-churn-prediction/WA_Fn-UseC_-Telco-Customer-Churn.csv
3.2 Data preparation
- Download the data, read it with pandas
- Look at the data
- Make column names and values look uniform
- Check if all the columns read correctly
- Check if the churn variable needs any preparation
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = 'https://raw.githubusercontent.com/alexeygrigorev/mlbookcamp-code/master/chapter-03-churn-prediction/WA_Fn-UseC_-Telco-Customer-Churn.csv'
df = pd.read_csv(r'E:\gito\mlbookcamp-code\chapter-03-churn-prediction\WA_Fn-UseC_-Telco-Customer-Churn.csv')
df.head()
| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | MultipleLines | InternetService | OnlineSecurity | ... | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | Contract | PaperlessBilling | PaymentMethod | MonthlyCharges | TotalCharges | Churn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG | Female | 0 | Yes | No | 1 | No | No phone service | DSL | No | ... | No | No | No | No | Month-to-month | Yes | Electronic check | 29.85 | 29.85 | No |
| 1 | 5575-GNVDE | Male | 0 | No | No | 34 | Yes | No | DSL | Yes | ... | Yes | No | No | No | One year | No | Mailed check | 56.95 | 1889.5 | No |
| 2 | 3668-QPYBK | Male | 0 | No | No | 2 | Yes | No | DSL | Yes | ... | No | No | No | No | Month-to-month | Yes | Mailed check | 53.85 | 108.15 | Yes |
| 3 | 7795-CFOCW | Male | 0 | No | No | 45 | No | No phone service | DSL | Yes | ... | Yes | Yes | No | No | One year | No | Bank transfer (automatic) | 42.30 | 1840.75 | No |
| 4 | 9237-HQITU | Female | 0 | No | No | 2 | Yes | No | Fiber optic | No | ... | No | No | No | No | Month-to-month | Yes | Electronic check | 70.70 | 151.65 | Yes |
5 rows × 21 columns
df.columns = df.columns.str.lower().str.replace(' ', '_')
categorical_columns = list(df.dtypes[df.dtypes == 'object'].index)
for c in categorical_columns:
df[c] = df[c].str.lower().str.replace(' ', '_')
df.head().T
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| customerid | 7590-vhveg | 5575-gnvde | 3668-qpybk | 7795-cfocw | 9237-hqitu |
| gender | female | male | male | male | female |
| seniorcitizen | 0 | 0 | 0 | 0 | 0 |
| partner | yes | no | no | no | no |
| dependents | no | no | no | no | no |
| tenure | 1 | 34 | 2 | 45 | 2 |
| phoneservice | no | yes | yes | no | yes |
| multiplelines | no_phone_service | no | no | no_phone_service | no |
| internetservice | dsl | dsl | dsl | dsl | fiber_optic |
| onlinesecurity | no | yes | yes | yes | no |
| onlinebackup | yes | no | yes | no | no |
| deviceprotection | no | yes | no | yes | no |
| techsupport | no | no | no | yes | no |
| streamingtv | no | no | no | no | no |
| streamingmovies | no | no | no | no | no |
| contract | month-to-month | one_year | month-to-month | one_year | month-to-month |
| paperlessbilling | yes | no | yes | no | yes |
| paymentmethod | electronic_check | mailed_check | mailed_check | bank_transfer_(automatic) | electronic_check |
| monthlycharges | 29.85 | 56.95 | 53.85 | 42.3 | 70.7 |
| totalcharges | 29.85 | 1889.5 | 108.15 | 1840.75 | 151.65 |
| churn | no | no | yes | no | yes |
tc = pd.to_numeric(df.totalcharges, errors='coerce')
df.totalcharges = pd.to_numeric(df.totalcharges, errors='coerce')
df.totalcharges = df.totalcharges.fillna(0)
df.churn.head()
0 no
1 no
2 yes
3 no
4 yes
Name: churn, dtype: object
df.churn = (df.churn == 'yes').astype(int)
3.3 Setting up the validation framework
- Perform the train/validation/test split with Scikit-Learn
from sklearn.model_selection import train_test_split
df_full_train, df_test = train_test_split(df, test_size=0.2, random_state=1)
df_train, df_val = train_test_split(df_full_train, test_size=0.25, random_state=1)
len(df_train), len(df_val), len(df_test)
(4225, 1409, 1409)
df_train = df_train.reset_index(drop=True)
df_val = df_val.reset_index(drop=True)
df_test = df_test.reset_index(drop=True)
y_train = df_train.churn.values
y_val = df_val.churn.values
y_test = df_test.churn.values
del df_train['churn']
del df_val['churn']
del df_test['churn']
3.4 EDA
- Check missing values
- Look at the target variable (churn)
- Look at numerical and categorical variables
df_full_train = df_full_train.reset_index(drop=True)
df_full_train.isnull().sum()
customerid 0
gender 0
seniorcitizen 0
partner 0
dependents 0
tenure 0
phoneservice 0
multiplelines 0
internetservice 0
onlinesecurity 0
onlinebackup 0
deviceprotection 0
techsupport 0
streamingtv 0
streamingmovies 0
contract 0
paperlessbilling 0
paymentmethod 0
monthlycharges 0
totalcharges 0
churn 0
dtype: int64
df_full_train.churn.value_counts(normalize=True)
0 0.730032
1 0.269968
Name: churn, dtype: float64
df_full_train.churn.mean()
0.26996805111821087
numerical = ['tenure', 'monthlycharges', 'totalcharges']
categorical = [
'gender',
'seniorcitizen',
'partner',
'dependents',
'phoneservice',
'multiplelines',
'internetservice',
'onlinesecurity',
'onlinebackup',
'deviceprotection',
'techsupport',
'streamingtv',
'streamingmovies',
'contract',
'paperlessbilling',
'paymentmethod',
]
df_full_train[categorical].nunique()
gender 2
seniorcitizen 2
partner 2
dependents 2
phoneservice 2
multiplelines 3
internetservice 3
onlinesecurity 3
onlinebackup 3
deviceprotection 3
techsupport 3
streamingtv 3
streamingmovies 3
contract 3
paperlessbilling 2
paymentmethod 4
dtype: int64
3.5 Feature importance: Churn rate and risk ratio
Feature importance analysis (part of EDA) - identifying which features affect our target variable
- Churn rate
- Risk ratio
- Mutual information - later
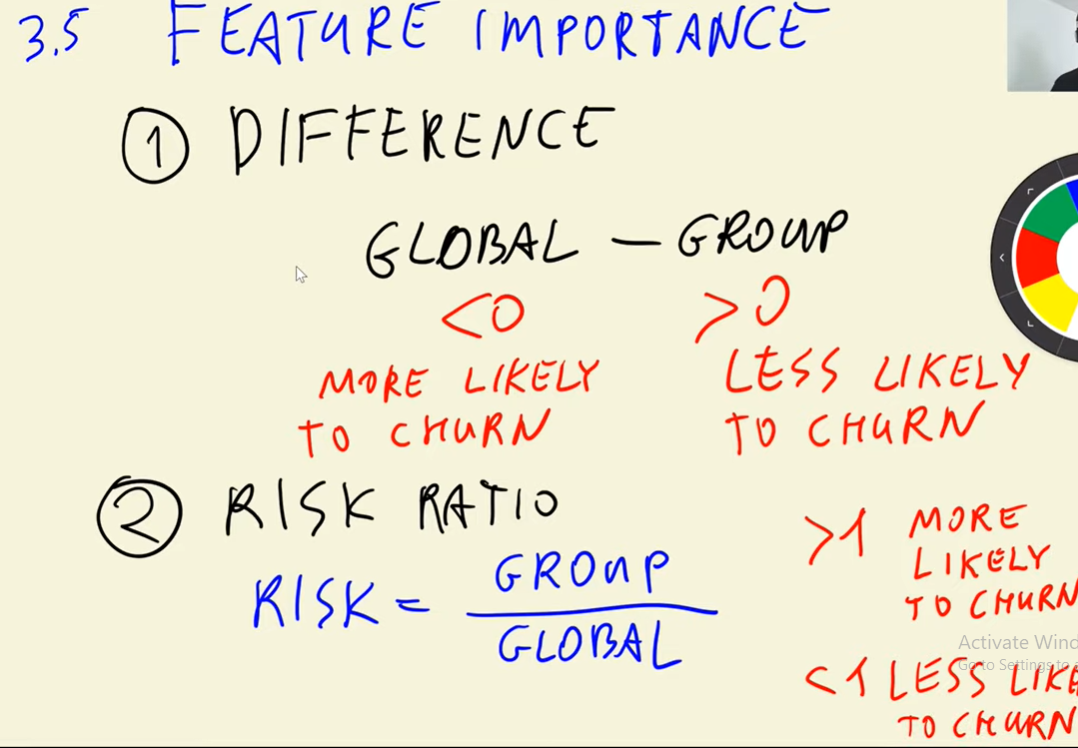
Churn rate
df_full_train.head()
| customerid | gender | seniorcitizen | partner | dependents | tenure | phoneservice | multiplelines | internetservice | onlinesecurity | ... | deviceprotection | techsupport | streamingtv | streamingmovies | contract | paperlessbilling | paymentmethod | monthlycharges | totalcharges | churn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5442-pptjy | male | 0 | yes | yes | 12 | yes | no | no | no_internet_service | ... | no_internet_service | no_internet_service | no_internet_service | no_internet_service | two_year | no | mailed_check | 19.70 | 258.35 | 0 |
| 1 | 6261-rcvns | female | 0 | no | no | 42 | yes | no | dsl | yes | ... | yes | yes | no | yes | one_year | no | credit_card_(automatic) | 73.90 | 3160.55 | 1 |
| 2 | 2176-osjuv | male | 0 | yes | no | 71 | yes | yes | dsl | yes | ... | no | yes | no | no | two_year | no | bank_transfer_(automatic) | 65.15 | 4681.75 | 0 |
| 3 | 6161-erdgd | male | 0 | yes | yes | 71 | yes | yes | dsl | yes | ... | yes | yes | yes | yes | one_year | no | electronic_check | 85.45 | 6300.85 | 0 |
| 4 | 2364-ufrom | male | 0 | no | no | 30 | yes | no | dsl | yes | ... | no | yes | yes | no | one_year | no | electronic_check | 70.40 | 2044.75 | 0 |
5 rows × 21 columns
churn_female = df_full_train[df_full_train.gender == 'female'].churn.mean()
churn_female
0.27682403433476394
churn_male = df_full_train[df_full_train.gender == 'male'].churn.mean()
churn_male
0.2632135306553911
global_churn = df_full_train.churn.mean()
global_churn
0.26996805111821087
global_churn - churn_female
-0.006855983216553063
global_churn - churn_male
0.006754520462819769
df_full_train.partner.value_counts()
no 2932
yes 2702
Name: partner, dtype: int64
churn_partner = df_full_train[df_full_train.partner == 'yes'].churn.mean()
churn_partner
0.20503330866025166
global_churn - churn_partner
0.06493474245795922
churn_no_partner = df_full_train[df_full_train.partner == 'no'].churn.mean()
churn_no_partner
0.3298090040927694
global_churn - churn_no_partner
-0.05984095297455855
Risk ratio
churn_no_partner / global_churn
1.2216593879412643
churn_partner / global_churn
0.7594724924338315
SELECT
gender,
AVG(churn),
AVG(churn) - global_churn AS diff,
AVG(churn) / global_churn AS risk
FROM
data
GROUP BY
gender;
from IPython.display import display
for c in categorical:
print(c)
df_group = df_full_train.groupby(c).churn.agg(['mean', 'count'])
df_group['diff'] = df_group['mean'] - global_churn
df_group['risk'] = df_group['mean'] / global_churn
display(df_group)
print()
print()
gender
| mean | count | diff | risk | |
|---|---|---|---|---|
| gender | ||||
| female | 0.276824 | 2796 | 0.006856 | 1.025396 |
| male | 0.263214 | 2838 | -0.006755 | 0.974980 |
seniorcitizen
| mean | count | diff | risk | |
|---|---|---|---|---|
| seniorcitizen | ||||
| 0 | 0.242270 | 4722 | -0.027698 | 0.897403 |
| 1 | 0.413377 | 912 | 0.143409 | 1.531208 |
partner
| mean | count | diff | risk | |
|---|---|---|---|---|
| partner | ||||
| no | 0.329809 | 2932 | 0.059841 | 1.221659 |
| yes | 0.205033 | 2702 | -0.064935 | 0.759472 |
dependents
| mean | count | diff | risk | |
|---|---|---|---|---|
| dependents | ||||
| no | 0.313760 | 3968 | 0.043792 | 1.162212 |
| yes | 0.165666 | 1666 | -0.104302 | 0.613651 |
phoneservice
| mean | count | diff | risk | |
|---|---|---|---|---|
| phoneservice | ||||
| no | 0.241316 | 547 | -0.028652 | 0.893870 |
| yes | 0.273049 | 5087 | 0.003081 | 1.011412 |
multiplelines
| mean | count | diff | risk | |
|---|---|---|---|---|
| multiplelines | ||||
| no | 0.257407 | 2700 | -0.012561 | 0.953474 |
| no_phone_service | 0.241316 | 547 | -0.028652 | 0.893870 |
| yes | 0.290742 | 2387 | 0.020773 | 1.076948 |
internetservice
| mean | count | diff | risk | |
|---|---|---|---|---|
| internetservice | ||||
| dsl | 0.192347 | 1934 | -0.077621 | 0.712482 |
| fiber_optic | 0.425171 | 2479 | 0.155203 | 1.574895 |
| no | 0.077805 | 1221 | -0.192163 | 0.288201 |
onlinesecurity
| mean | count | diff | risk | |
|---|---|---|---|---|
| onlinesecurity | ||||
| no | 0.420921 | 2801 | 0.150953 | 1.559152 |
| no_internet_service | 0.077805 | 1221 | -0.192163 | 0.288201 |
| yes | 0.153226 | 1612 | -0.116742 | 0.567570 |
onlinebackup
| mean | count | diff | risk | |
|---|---|---|---|---|
| onlinebackup | ||||
| no | 0.404323 | 2498 | 0.134355 | 1.497672 |
| no_internet_service | 0.077805 | 1221 | -0.192163 | 0.288201 |
| yes | 0.217232 | 1915 | -0.052736 | 0.804660 |
deviceprotection
| mean | count | diff | risk | |
|---|---|---|---|---|
| deviceprotection | ||||
| no | 0.395875 | 2473 | 0.125907 | 1.466379 |
| no_internet_service | 0.077805 | 1221 | -0.192163 | 0.288201 |
| yes | 0.230412 | 1940 | -0.039556 | 0.853480 |
techsupport
| mean | count | diff | risk | |
|---|---|---|---|---|
| techsupport | ||||
| no | 0.418914 | 2781 | 0.148946 | 1.551717 |
| no_internet_service | 0.077805 | 1221 | -0.192163 | 0.288201 |
| yes | 0.159926 | 1632 | -0.110042 | 0.592390 |
streamingtv
| mean | count | diff | risk | |
|---|---|---|---|---|
| streamingtv | ||||
| no | 0.342832 | 2246 | 0.072864 | 1.269897 |
| no_internet_service | 0.077805 | 1221 | -0.192163 | 0.288201 |
| yes | 0.302723 | 2167 | 0.032755 | 1.121328 |
streamingmovies
| mean | count | diff | risk | |
|---|---|---|---|---|
| streamingmovies | ||||
| no | 0.338906 | 2213 | 0.068938 | 1.255358 |
| no_internet_service | 0.077805 | 1221 | -0.192163 | 0.288201 |
| yes | 0.307273 | 2200 | 0.037305 | 1.138182 |
contract
| mean | count | diff | risk | |
|---|---|---|---|---|
| contract | ||||
| month-to-month | 0.431701 | 3104 | 0.161733 | 1.599082 |
| one_year | 0.120573 | 1186 | -0.149395 | 0.446621 |
| two_year | 0.028274 | 1344 | -0.241694 | 0.104730 |
paperlessbilling
| mean | count | diff | risk | |
|---|---|---|---|---|
| paperlessbilling | ||||
| no | 0.172071 | 2313 | -0.097897 | 0.637375 |
| yes | 0.338151 | 3321 | 0.068183 | 1.252560 |
paymentmethod
| mean | count | diff | risk | |
|---|---|---|---|---|
| paymentmethod | ||||
| bank_transfer_(automatic) | 0.168171 | 1219 | -0.101797 | 0.622928 |
| credit_card_(automatic) | 0.164339 | 1217 | -0.105630 | 0.608733 |
| electronic_check | 0.455890 | 1893 | 0.185922 | 1.688682 |
| mailed_check | 0.193870 | 1305 | -0.076098 | 0.718121 |
3.6 Feature importance: Mutual information
Mutual information - concept from information theory, it tells us how much we can learn about one variable if we know the value of another
- https://en.wikipedia.org/wiki/Mutual_information
from sklearn.metrics import mutual_info_score
mutual_info_score(df_full_train.churn, df_full_train.contract)
0.0983203874041556
mutual_info_score(df_full_train.gender, df_full_train.churn)
0.0001174846211139946
mutual_info_score(df_full_train.contract, df_full_train.churn)
0.0983203874041556
mutual_info_score(df_full_train.partner, df_full_train.churn)
0.009967689095399745
def mutual_info_churn_score(series):
return mutual_info_score(series, df_full_train.churn)
mi = df_full_train[categorical].apply(mutual_info_churn_score)
mi.sort_values(ascending=False)
contract 0.098320
onlinesecurity 0.063085
techsupport 0.061032
internetservice 0.055868
onlinebackup 0.046923
deviceprotection 0.043453
paymentmethod 0.043210
streamingtv 0.031853
streamingmovies 0.031581
paperlessbilling 0.017589
dependents 0.012346
partner 0.009968
seniorcitizen 0.009410
multiplelines 0.000857
phoneservice 0.000229
gender 0.000117
dtype: float64
3.7 Feature importance: Correlation
How about numerical columns?
- Correlation coefficient - https://en.wikipedia.org/wiki/Pearson_correlation_coefficient
df_full_train.tenure.max()
72
df_full_train[numerical].corrwith(df_full_train.churn).abs()
tenure 0.351885
monthlycharges 0.196805
totalcharges 0.196353
dtype: float64
df_full_train[df_full_train.tenure <= 2].churn.mean()
0.5953420669577875
df_full_train[(df_full_train.tenure > 2) & (df_full_train.tenure <= 12)].churn.mean()
0.3994413407821229
df_full_train[df_full_train.tenure > 12].churn.mean()
0.17634908339788277
df_full_train[df_full_train.monthlycharges <= 20].churn.mean()
0.08795411089866156
df_full_train[(df_full_train.monthlycharges > 20) & (df_full_train.monthlycharges <= 50)].churn.mean()
0.18340943683409436
df_full_train[df_full_train.monthlycharges > 50].churn.mean()
0.32499341585462205
3.8 One-hot encoding
- Use Scikit-Learn to encode categorical features
from sklearn.feature_extraction import DictVectorizer
dv = DictVectorizer(sparse=False)
train_dict = df_train[categorical + numerical].to_dict(orient='records')
X_train = dv.fit_transform(train_dict)
val_dict = df_val[categorical + numerical].to_dict(orient='records')
X_val = dv.transform(val_dict)
3.9 Logistic regression
- Binary classification
- Linear vs logistic regression
def sigmoid(z):
return 1 / (1 + np.exp(-z))
z = np.linspace(-7, 7, 51)
sigmoid(10000)
1.0
plt.plot(z, sigmoid(z))
[<matplotlib.lines.Line2D at 0x7f342d0bf080>]

def linear_regression(xi):
result = w0
for j in range(len(w)):
result = result + xi[j] * w[j]
return result
def logistic_regression(xi):
score = w0
for j in range(len(w)):
score = score + xi[j] * w[j]
result = sigmoid(score)
return result
3.10 Training logistic regression with Scikit-Learn
- Train a model with Scikit-Learn
- Apply it to the validation dataset
- Calculate the accuracy
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(solver='lbfgs')
# solver='lbfgs' is the default solver in newer version of sklearn
# for older versions, you need to specify it explicitly
model.fit(X_train, y_train)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='warn', n_jobs=None, penalty='l2',
random_state=None, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)
model.intercept_[0]
-0.10903395348323511
model.coef_[0].round(3)
array([ 0.475, -0.175, -0.408, -0.03 , -0.078, 0.063, -0.089, -0.081,
-0.034, -0.073, -0.335, 0.316, -0.089, 0.004, -0.258, 0.141,
0.009, 0.063, -0.089, -0.081, 0.266, -0.089, -0.284, -0.231,
0.124, -0.166, 0.058, -0.087, -0.032, 0.07 , -0.059, 0.141,
-0.249, 0.215, -0.12 , -0.089, 0.102, -0.071, -0.089, 0.052,
0.213, -0.089, -0.232, -0.07 , 0. ])
y_pred = model.predict_proba(X_val)[:, 1]
churn_decision = (y_pred >= 0.5)
(y_val == churn_decision).mean()
0.8034066713981547
df_pred = pd.DataFrame()
df_pred['probability'] = y_pred
df_pred['prediction'] = churn_decision.astype(int)
df_pred['actual'] = y_val
df_pred['correct'] = df_pred.prediction == df_pred.actual
df_pred.correct.mean()
0.8034066713981547
churn_decision.astype(int)
array([0, 0, 0, ..., 0, 1, 1])
3.11 Model interpretation
- Look at the coefficients
- Train a smaller model with fewer features
a = [1, 2, 3, 4]
b = 'abcd'
dict(zip(a, b))
{1: 'a', 2: 'b', 3: 'c', 4: 'd'}
dict(zip(dv.get_feature_names(), model.coef_[0].round(3)))
{'contract=month-to-month': 0.475,
'contract=one_year': -0.175,
'contract=two_year': -0.408,
'dependents=no': -0.03,
'dependents=yes': -0.078,
'deviceprotection=no': 0.063,
'deviceprotection=no_internet_service': -0.089,
'deviceprotection=yes': -0.081,
'gender=female': -0.034,
'gender=male': -0.073,
'internetservice=dsl': -0.335,
'internetservice=fiber_optic': 0.316,
'internetservice=no': -0.089,
'monthlycharges': 0.004,
'multiplelines=no': -0.258,
'multiplelines=no_phone_service': 0.141,
'multiplelines=yes': 0.009,
'onlinebackup=no': 0.063,
'onlinebackup=no_internet_service': -0.089,
'onlinebackup=yes': -0.081,
'onlinesecurity=no': 0.266,
'onlinesecurity=no_internet_service': -0.089,
'onlinesecurity=yes': -0.284,
'paperlessbilling=no': -0.231,
'paperlessbilling=yes': 0.124,
'partner=no': -0.166,
'partner=yes': 0.058,
'paymentmethod=bank_transfer_(automatic)': -0.087,
'paymentmethod=credit_card_(automatic)': -0.032,
'paymentmethod=electronic_check': 0.07,
'paymentmethod=mailed_check': -0.059,
'phoneservice=no': 0.141,
'phoneservice=yes': -0.249,
'seniorcitizen': 0.215,
'streamingmovies=no': -0.12,
'streamingmovies=no_internet_service': -0.089,
'streamingmovies=yes': 0.102,
'streamingtv=no': -0.071,
'streamingtv=no_internet_service': -0.089,
'streamingtv=yes': 0.052,
'techsupport=no': 0.213,
'techsupport=no_internet_service': -0.089,
'techsupport=yes': -0.232,
'tenure': -0.07,
'totalcharges': 0.0}
small = ['contract', 'tenure', 'monthlycharges']
df_train[small].iloc[:10].to_dict(orient='records')
[{'contract': 'two_year', 'tenure': 72, 'monthlycharges': 115.5},
{'contract': 'month-to-month', 'tenure': 10, 'monthlycharges': 95.25},
{'contract': 'month-to-month', 'tenure': 5, 'monthlycharges': 75.55},
{'contract': 'month-to-month', 'tenure': 5, 'monthlycharges': 80.85},
{'contract': 'two_year', 'tenure': 18, 'monthlycharges': 20.1},
{'contract': 'month-to-month', 'tenure': 4, 'monthlycharges': 30.5},
{'contract': 'month-to-month', 'tenure': 1, 'monthlycharges': 75.1},
{'contract': 'month-to-month', 'tenure': 1, 'monthlycharges': 70.3},
{'contract': 'two_year', 'tenure': 72, 'monthlycharges': 19.75},
{'contract': 'month-to-month', 'tenure': 6, 'monthlycharges': 109.9}]
dicts_train_small = df_train[small].to_dict(orient='records')
dicts_val_small = df_val[small].to_dict(orient='records')
dv_small = DictVectorizer(sparse=False)
dv_small.fit(dicts_train_small)
DictVectorizer(dtype=<class 'numpy.float64'>, separator='=', sort=True,
sparse=False)
dv_small.get_feature_names()
['contract=month-to-month',
'contract=one_year',
'contract=two_year',
'monthlycharges',
'tenure']
X_train_small = dv_small.transform(dicts_train_small)
model_small = LogisticRegression(solver='lbfgs')
model_small.fit(X_train_small, y_train)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='warn', n_jobs=None, penalty='l2',
random_state=None, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)
w0 = model_small.intercept_[0]
w0
-2.476775657751665
w = model_small.coef_[0]
w.round(3)
array([ 0.97 , -0.025, -0.949, 0.027, -0.036])
dict(zip(dv_small.get_feature_names(), w.round(3)))
{'contract=month-to-month': 0.97,
'contract=one_year': -0.025,
'contract=two_year': -0.949,
'monthlycharges': 0.027,
'tenure': -0.036}
-2.47 + (-0.949) + 30 * 0.027 + 24 * (-0.036)
-3.473
sigmoid(_)
0.030090303318277657
3.12 Using the model
dicts_full_train = df_full_train[categorical + numerical].to_dict(orient='records')
dv = DictVectorizer(sparse=False)
X_full_train = dv.fit_transform(dicts_full_train)
y_full_train = df_full_train.churn.values
model = LogisticRegression(solver='lbfgs')
model.fit(X_full_train, y_full_train)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='warn', n_jobs=None, penalty='l2',
random_state=None, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)
dicts_test = df_test[categorical + numerical].to_dict(orient='records')
X_test = dv.transform(dicts_test)
y_pred = model.predict_proba(X_test)[:, 1]
churn_decision = (y_pred >= 0.5)
(churn_decision == y_test).mean()
0.815471965933286
y_test
array([0, 0, 0, ..., 0, 0, 1])
customer = dicts_test[-1]
customer
{'gender': 'female',
'seniorcitizen': 0,
'partner': 'yes',
'dependents': 'yes',
'phoneservice': 'yes',
'multiplelines': 'yes',
'internetservice': 'fiber_optic',
'onlinesecurity': 'yes',
'onlinebackup': 'no',
'deviceprotection': 'yes',
'techsupport': 'no',
'streamingtv': 'yes',
'streamingmovies': 'yes',
'contract': 'month-to-month',
'paperlessbilling': 'yes',
'paymentmethod': 'electronic_check',
'tenure': 17,
'monthlycharges': 104.2,
'totalcharges': 1743.5}
X_small = dv.transform([customer])
model.predict_proba(X_small)[0, 1]
0.5968852088293909
y_test[-1]
1
